Examples¶
axpy Function¶
This example illustrates how an axpy function could be implemented. The axpy function calculates
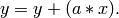
Please note that there exists an axpy function that is based on the CUDA BLAS library. This is an example that illustrated how all the features of the MGPU library work together: containers, communication, kernel invocation and synchronization.
First up is the kernel and a thin kernel caller function. The kernel caller takes as an argument two device ranges X and Y and a constant a. The kernel caller calculates the correct number of threads and blocks that are required to calculate the result. In this example the number of threads per block is fixed to 256. The number of blocks is calculated from the vector size. The caller passes a, two raw pointers and the size of the vectors to the kernel.
// axpy CUDA kernel code
__global__ void axpy_kernel(
float const a, float * X, float * Y, std::size_t size)
{
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < size) Y[i] = (a * X[i]) + Y[i];
}
// axpy CUDA kernel launcher
void axpy(float const a, dev_range<float> X, dev_range<float> Y)
{
assert(X.size() == Y.size());
int T = 256;
int B = (X.size() + T - 1) / T;
axpy_kernel<<< B, T >>>(
a, X.get_raw_pointer(), Y.get_raw_pointer(), Y.size());
}
The kernel itself calculates the array position i it has to work with, checks that it is not greater than the vector size and performs the calculation. The following section shows the main function that prepares the data and invokes the kernel.
const std::size_t size = 1024;
environment e;
{
ublas::vector<float> X(size), Y(size), Y_gold(size);
float const a = .42;
std::generate(X.begin(), X.end(), random_number);
std::generate(Y.begin(), Y.end(), random_number);
Y_gold = Y;
seg_dev_vector<float> X_dev(size), Y_dev(size);
copy(X, X_dev.begin()); copy(Y, Y_dev.begin());
// calculate on devices
invoke_kernel_all(axpy, a, X_dev, Y_dev);
copy(Y_dev, Y.begin());
synchronize_barrier();
// gold result (using boost::numeric)
Y_gold += a * X;
// compare result
bool equal = true;
for(unsigned int i=0; i<Y.size(); i++)
{ equal &= rough_eq(Y_gold[i], Y[i], .0001); }
if(equal) printf("test ok\n"); else printf("test not ok\n");
}
The MGPU library is compatible with Boost.Numeric containers. We show the compatibility here and also use it to calculate a gold result on the host to verify the device code. First we create the X and Y vectors and a third vector to store the host result Y_gold. We fill the vectors with random numbers and transfer them to equivalent segmented device vectors X_dev and Y_dev. Note that the use of the segmented device vector automatically distributes the vector across all devices. Next we invoke the kernel caller. We pass the function we want to invoke and its arguments to the invoke_kernel_all function. This will call the function for each device in each device thread and context. The segmented device vector function arguments are transformed to local device ranges - each range contains the local vector. After the computation is finished we transfer the result back to host memory and we call synchronize_barrier to make sure all operations finished and the data was copied to host memory. We finally perform the same computation on the host and compare the results.
The full code can be found in the example directory in file axpy.cu.